Our project draws on several datasets hosted by the MIT Election Lab. Primary Source: https://electionlab.mit.edu/data
Data Sources:
Presidential Election Results (1976-2020) Source: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/42MVDX Description: This dataset contains state-level presidential election results, including vote counts for major parties, minor parties, and independent candidates. It provides data on total votes cast, voter turnout, and percentage share of each candidate in every presidential election from 1976 to 2020. Data Format: CSV file with columns for state, year, candidate, party, vote count, percentage share, and total votes cast. Frequency of Updates: Static dataset last updated to include results through 2020. Dimensions: Rows represent individual state-election combinations, with thousands of records. Planned Import: Data will be imported into R Studio using the read.csv function.
Senate Election Results (1976-2020) Source: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/PEJ5QU Description: This dataset provides results for Senate elections, including candidate vote counts, party affiliations, and special elections. Data covers statewide elections and includes party-specific turnout information. Data Format: CSV file with columns for state, year, candidate, party, votes, percentage share, and whether the election was a regular or special election. Frequency of Updates: Static dataset last updated to include results through 2020. Dimensions: State-year combinations with additional rows for runoff elections. Planned Import: Data will be imported into R Studio using the read.csv function.
House Election Results (1976-2022) Source: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/IG0UN2 Description: This dataset includes congressional district-level results for House elections, with details on candidates, vote counts, and party affiliations. Data Format: CSV file with columns for district, state, year, candidate, party, vote count, and total votes. Frequency of Updates: Static dataset last updated to include results through 2022. Dimensions: Rows represent congressional district-year combinations, totaling tens of thousands of records. Planned Import: Data will be imported into R Studio using the read.csv function.
Issues/Problems:
Temporal Mismatch: The House election data extends through 2022, while presidential and Senate data only go up to 2020. To ensure consistency, we will analyze all datasets only up to 2020. Runoff Election Data: Significant missing data exists for runoff elections, particularly in Senate and House results. This component will be excluded from the analysis to maintain data reliability. Granularity: While presidential data is state-level, House data is district-level. This mismatch in granularity may limit the scope of comparative analyses. Aggregation or normalization may be necessary in some cases. Data Quality: There are missing or incomplete fields in some years for minor-party candidates and inconsistencies in party naming conventions across datasets.
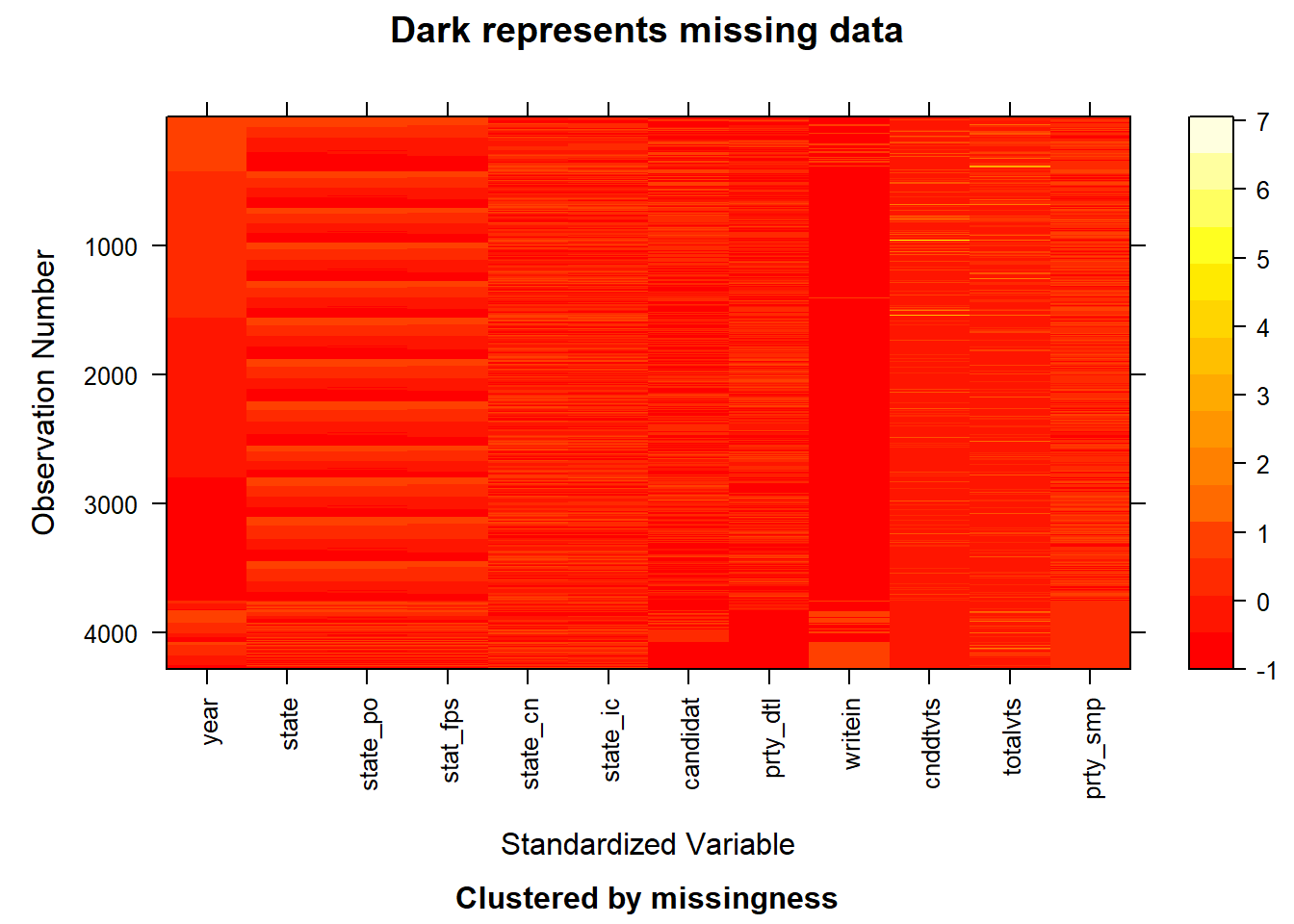
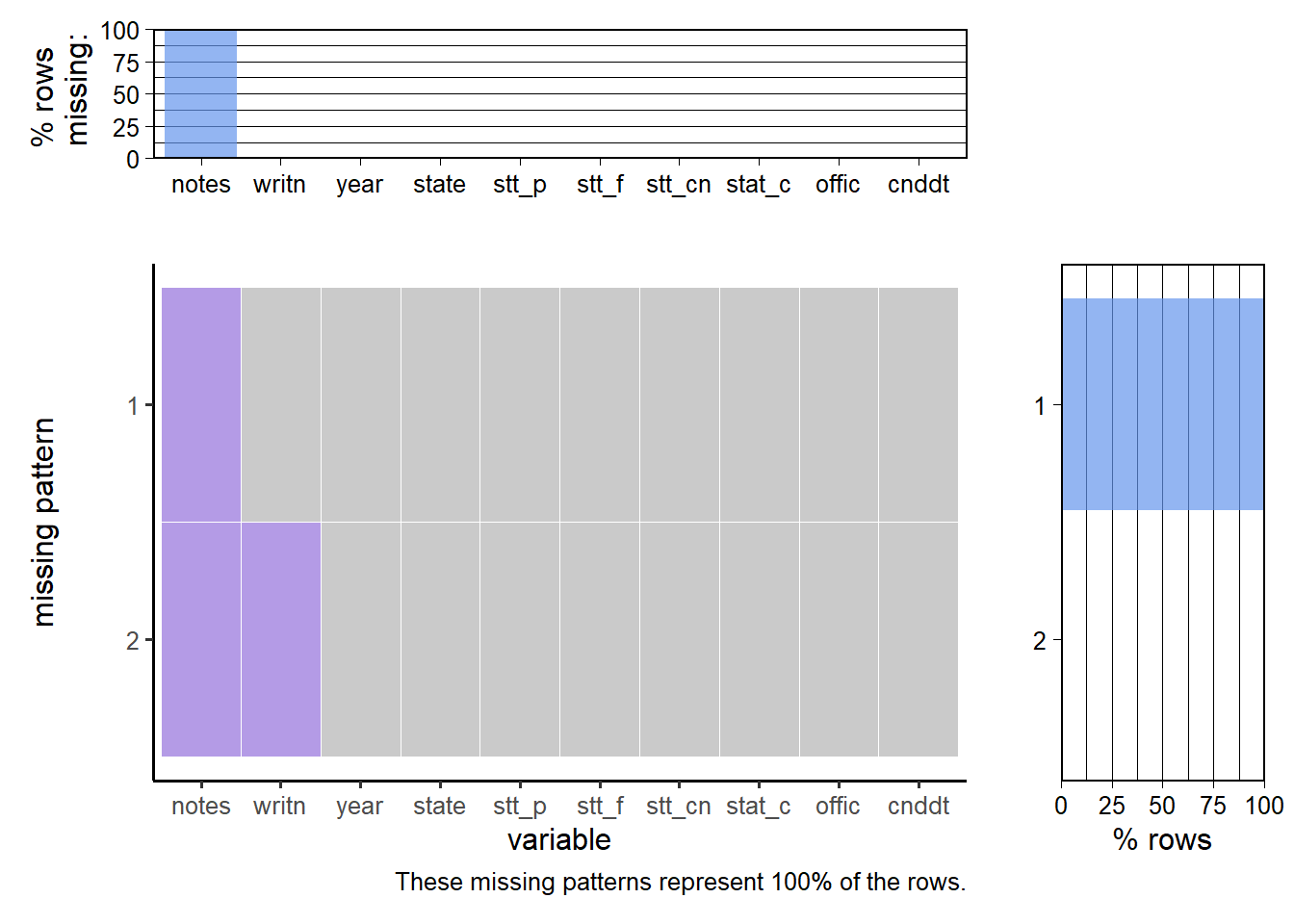
The visualization of missing values in the presidential election dataset reveals that most variables are complete, with no missing values, such as year, state, and totalvotes. However, the notes variable is entirely missing (100%), which likely indicates that there were no special remarks or annotations needed for the observations. Given its lack of content and relevance, we have decided to remove this column from the dataset to streamline the analysis. Additionally, the writein variable shows a very small proportion of missing values (less than 0.1%), which are unlikely to significantly impact the dataset’s overall integrity. We have removed the rows containing these missing values to maintain the integrity of the analysis. (The first plot does not display ‘note’ as all values are missing. To keep the image clean, the second plot displays only 10 variables.)
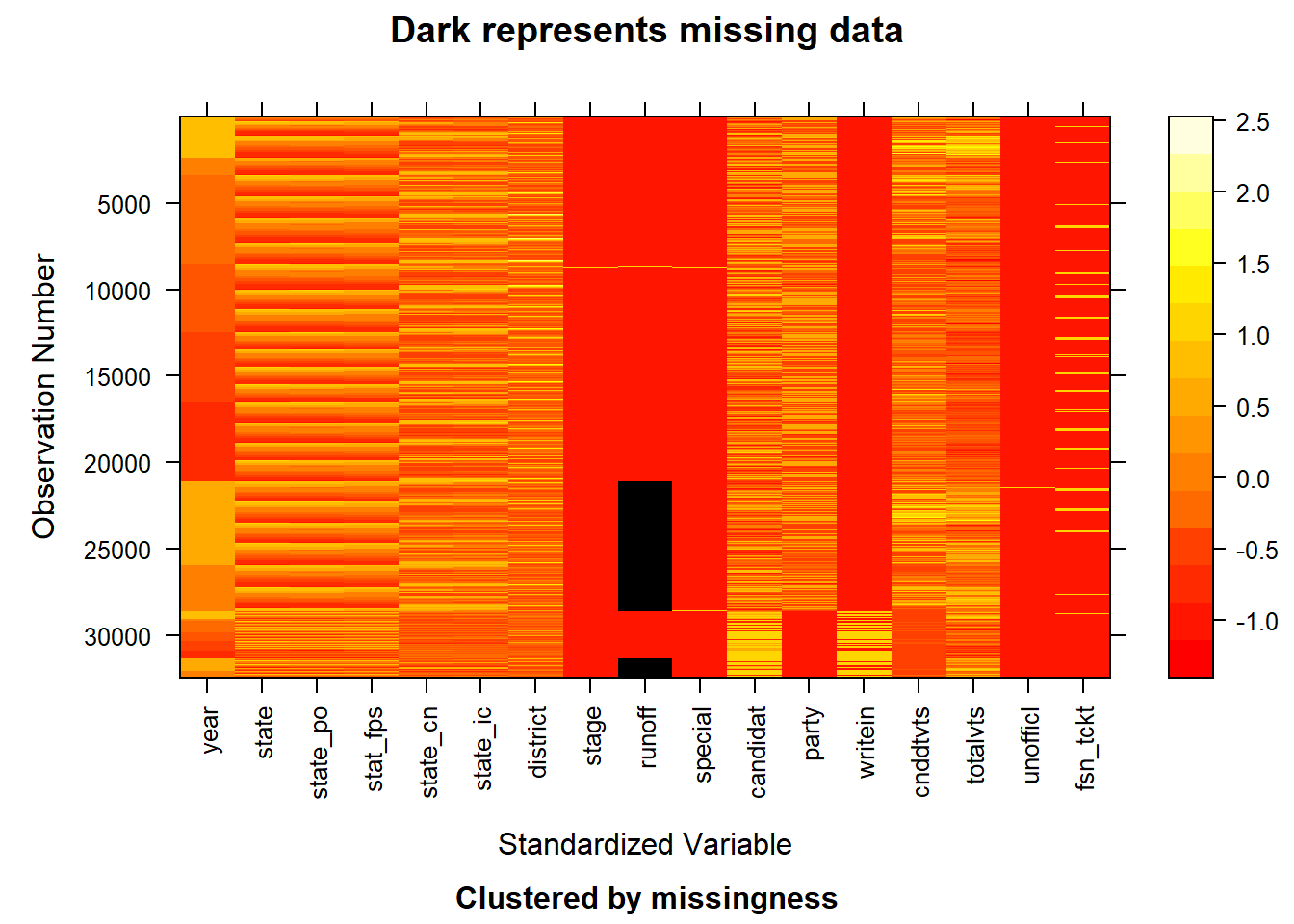
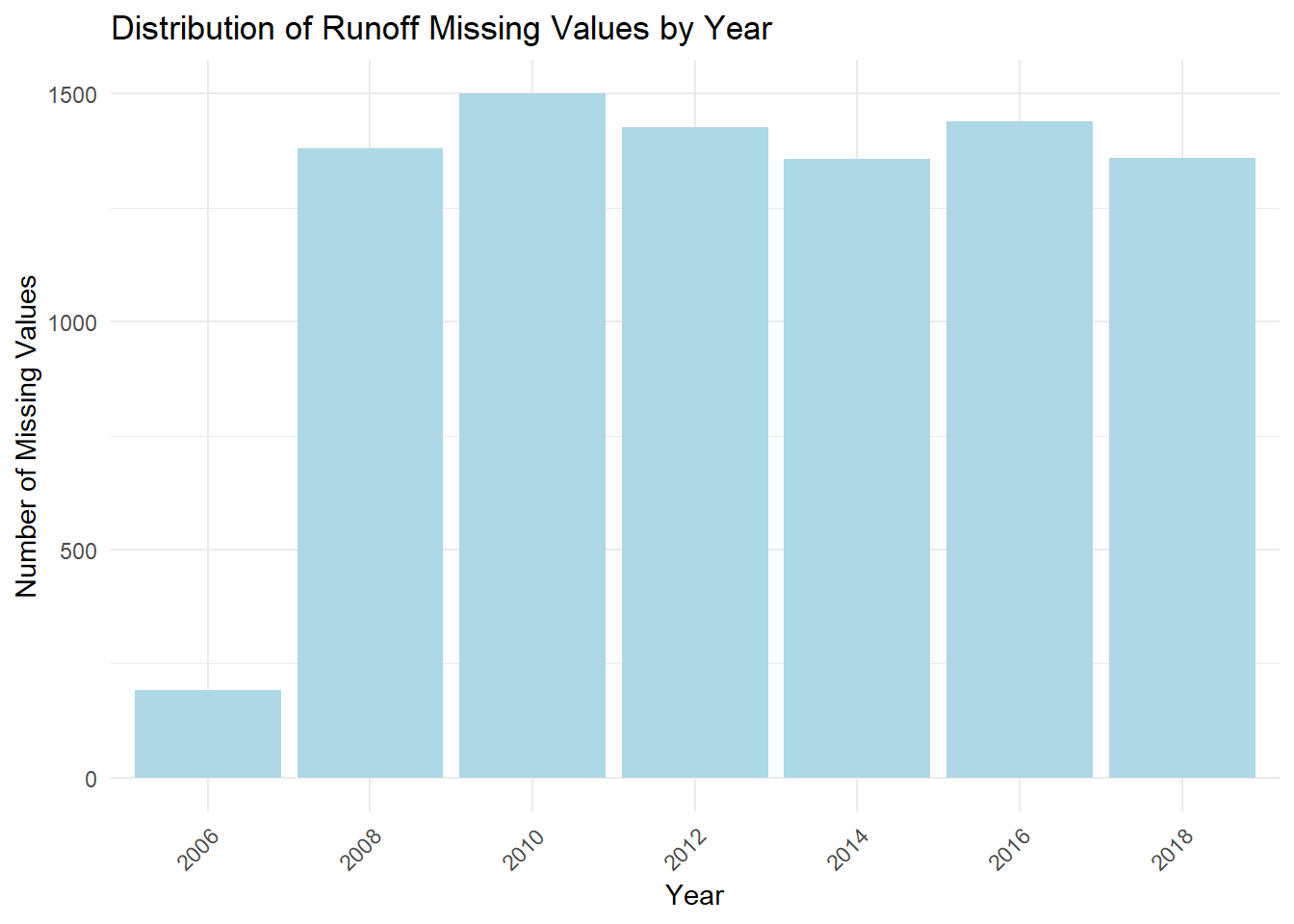
The plot shows that the missing values in the runoff column are distributed relatively evenly across the years, suggesting that the missing data may be due to inconsistencies or issues in the data collection process. Given the high percentage of missing values in this column (28%) and its relatively low importance for our analysis, we have decided to remove the runoff column entirely to streamline the dataset and focus on more relevant variables. (To keep the image clean, the third plot displays only 10 variables.)
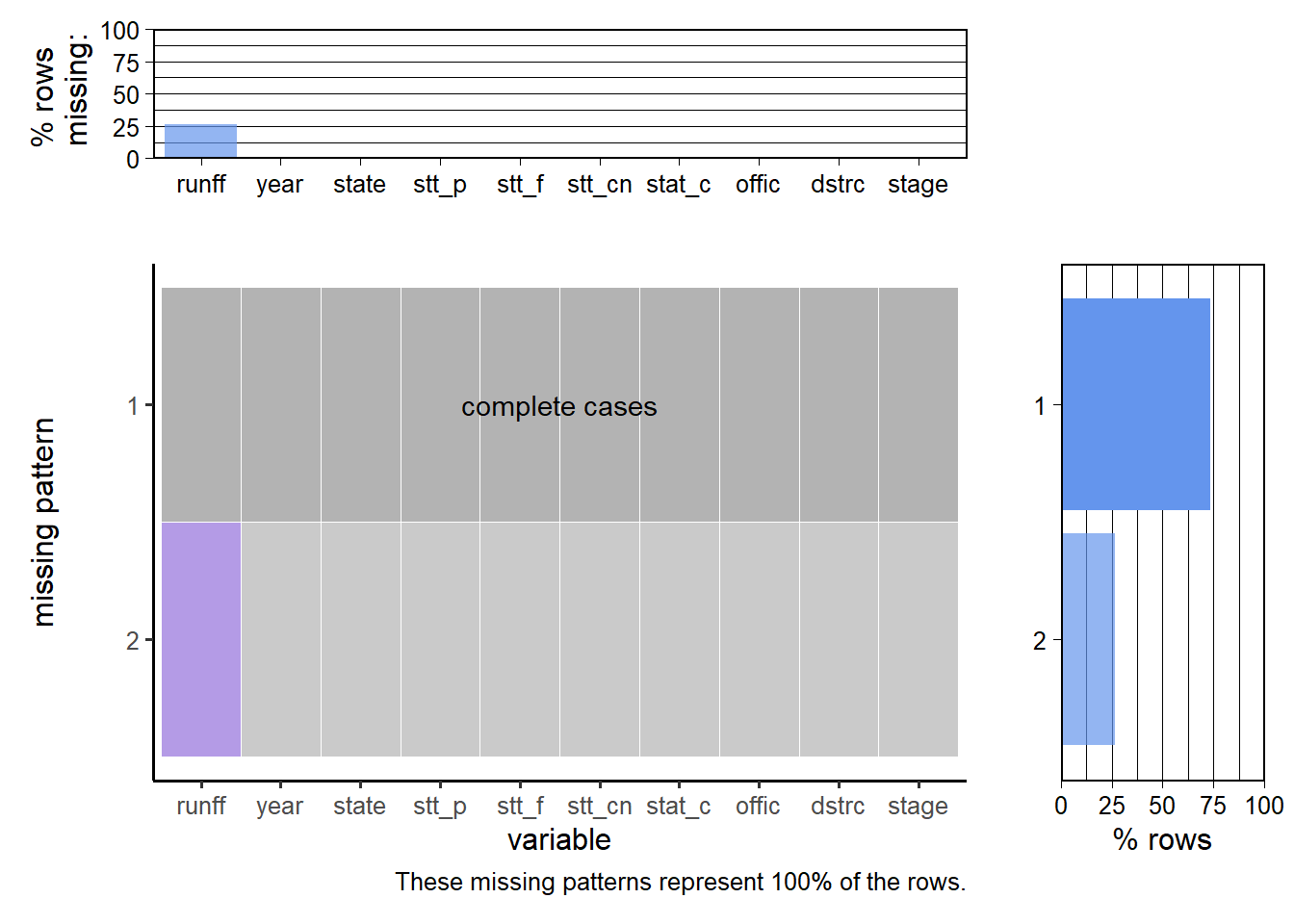
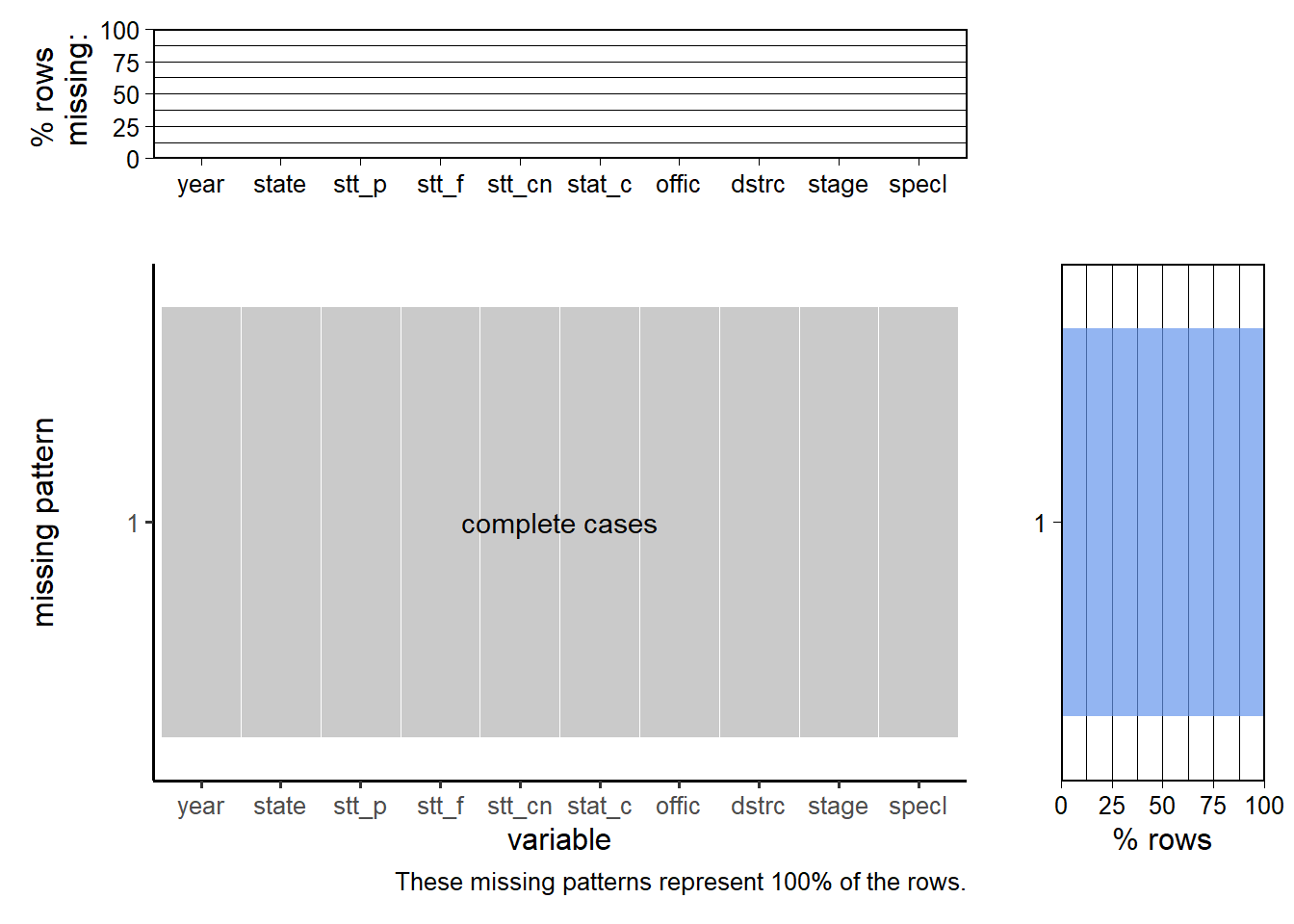
The plot shows that there are no missing values in senate data, so we do not make any modification to this data. (To keep the image clean, the plot displays only 10 variables.)